Introduction to MongoDB Atlas Vector Search with lang chain


Generative AI | Artificial Intelligence | LangChain | MongoDB
Vector embeddings are like compact representations of data, consisting of arrays of floating-point numbers. While they may seem small individually, when you have to manage thousands of them, storage and comparison become significant concerns. Many databases aren't optimized for handling such vectors efficiently, leading to performance bottlenecks.
Moreover, using embeddings typically involves continuous generation and integration with models like Google Cloud's textembedding-gecko. This transformer-based model produces high-dimensional vectors capturing semantic meaning and context from text and code. For instance, integrating it could mean generating embeddings for customer reviews and product ratings to enhance customer churn prediction models.
Despite their utility, efficiently storing and querying vector embeddings presents challenges. Specialized vector databases offer solutions, but they bring their own complexities—from syncing with operational databases to learning new technologies and incurring extra costs.
Enter MongoDB Atlas Vector Search—a solution that bridges the gap. By storing vectors within your existing operational database and leveraging MongoDB Atlas's capabilities, you can enjoy the performance benefits of specialized vector stores without the overhead of managing separate systems.
MongoDB Atlas, a fully-managed developer data platform, seamlessly integrates with Google Cloud AI services. Its array of features, including global deployments, automated data tiering, and elastic serverless instances, make it a compelling choice. With Vector Search, you can efficiently store, index, and query vector embeddings using MongoDB Atlas's familiar syntax and powerful query engine.
Store vector efficiently-
MongoDB Atlas introduced full-text search functionality back in 2020, albeit limited to a robust keyword matching algorithm. Recently, Mongo-db noticed a trend among users integrating vector databases with MongoDB Atlas, essentially converting their data into text embeddings. However, this setup led to synchronization challenges between operational data and vector storage, resulting in inefficiencies.
Recognizing this, we seized the opportunity to streamline these processes and minimize overhead. Many of developers were already leveraging MongoDB Atlas to store chat logs from LLM-based chatbots, generating vast amounts of unstructured data—a domain in which we excel. Atlas already augmented their platform to support chat log storage, given its flexible schema capable of accommodating diverse prompts and responses.
Now, in addition to the standard unstructured data, you can create an index definition on top of your collection that says where the vector fields are. Those vectors live right alongside the operational data—no syncing needed. This makes all your new chat log data available for approximate nearest neighbor algorithms. You’ll have to figure out an intelligent chunking strategy and bring your own embedding model, but that’s pretty standard if you’re looking to add data to a chatbot.
Every LLM is bounded by the training data it uses, and that training data has a cutoff date. With custom embeddings, customers can now provide up to date context for the model to use during inference. With the integrations built into frameworks like LangChain and LlamaIndex, developers can connect their private data to LLMs. Our community was so excited about the new capabilities in Atlas Vector Search that they provided the first commits to enable these frameworks.
MongoDB Atlas Vector Search has the following benefits :
- Speed up the process of indexing data for generative AI applications.
- Enhance the precision of information retrieval for generative AI applications.
- Real-time data streams from multiple sources can be used for AI-powered applications.
Vector search engines determine similarity based on distances within the embedding dimensions, departing from traditional keyword matching and word frequency approaches. Instead of relying on lexical matches, they seek the nearest neighbors of a query to find related data. Contextual and numerical representations in dense vectors preserve data essence. These embeddings stem from various models, proprietary (e.g., OpenAI, Hugging Face) or open-source (e.g., FastText), trained on millions of samples for relevance and precision. Whether utilizing collected numeric data or designing embeddings to highlight document characteristics, an efficient search mechanism, exemplified by MongoDB Atlas, proves indispensable.
LangChain and MongoDB:
MongoDB integrates nicely with LangChain because of the semantic search capabilities provided by MongoDB Atlas’s vector search engine. This allows for the perfect combination where users can query based on meaning rather than by specific words! Apart from MongoDB LangChain Python integration and MongoDB LangChain Javascript integration, MongoDB recently partnered with LangChain on the LangChain templates release to make it easier for developers to build AI-powered apps.
How to Perform Semantic Search Against Data in Your Atlas Cluster-
A Step-by-Step Guide
Prerequisites for success
- MongoDB Atlas account
- OpenAI API account and your API key
- IDE of your choice (this tutorial uses Google Colab)
1. Create a MongoDB Atlas Cluster :
To create a MongoDB Atlas cluster, follow the instructions in the MongoDB Atlas documentation.
2. Create Database :
By convention, we keep all data in the same MongoDB database.
However, you could theoretically use separate databases for collections, if you want to.
You can give the database any name you want. You pass the name as a variable throughout the RAG framework.
3. Importing and Initialization -
Semantic search in LangChain-
1-Install Library-
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import MongoDBAtlasVectorSearch
import os
from dotenv import load_dotenv
from pymongo import MongoClient
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import
RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.llms import OpenAI
2-Initialize MongoDB client and databasemongo_client-
OPENAI_API_KEY = os.environ["OPENAI_API_KEY"]
MONGO_URI = os.environ["MONGO_URI"]
DB_NAME = "langchain-test-2"
COLLECTION_NAME = "test"
ATLAS_VECTOR_SEARCH_INDEX_NAME = "default"
client = MongoClient(MONGO_URI)
db = client[DB_NAME]
collection = db[COLLECTION_NAME]
3- Initialize embeddings-
openai_api_key="enter your api key"
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
4- Loading the data-
loader = PyPDFLoader("use your pdf path here")
data = loader.load()
5- Text-Splitter-
text_splitter = RecursiveCharacterTextSplitter(chunk_size =
500,chunk_overlap = 50)
docs = text_splitter.split_documents(data)
6- insert the documents in MongoDB Atlas Vector Search-
x = MongoDBAtlasVectorSearch.from_documents(documents=docs,
embedding=OpenAIEmbeddings(disallowed_special=()),
collection=MONGODB_COLLECTION,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME
)
4. Creating our search index :
Let’s head over to MongoDB Atlas user interface to create our Vector Search Index. First, click on the “Search” tab and then on “Create Search Index.” You’ll be taken to this page. Please click on “JSON Editor.”
Ensure that the appropriate database and collection are selected, and verify the correct index name chosen as defined earlier. Then, paste in the search index designated for this tutorial.
{
"fields": [
{
"type": "vector",
"path": "embedding",
"numDimensions": 1536,
"similarity": "cosine"
},
{
"type": "filter",
"path": "source"
}
]
}
Once set up, it’ll look like this:
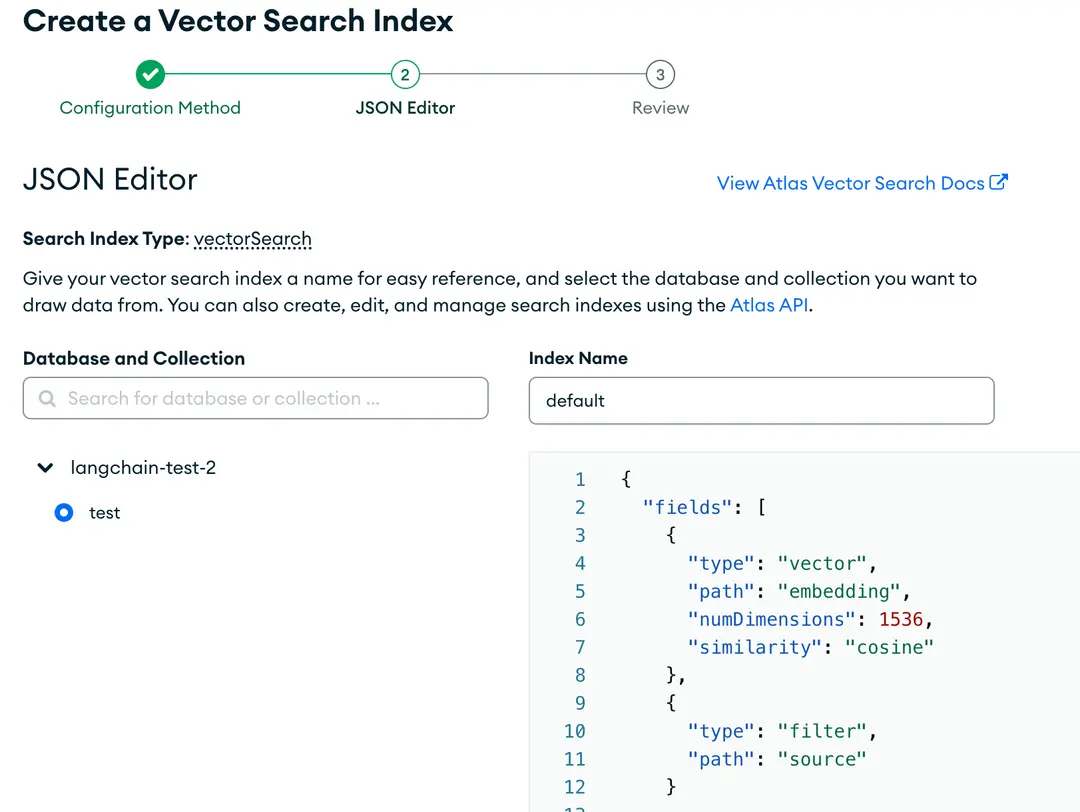
5. Semantic search in LangChain
vector_search = MongoDBAtlasVectorSearch.from_connection_string(
MONGO_URI,
DB_NAME + "." + COLLECTION_NAME,
OpenAIEmbeddings(disallowed_special=()),
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME
)
Define the Query:-
query = "gpt4?"
results = vector_search.similarity_search(
query=query,
k=20,
)
for result in results:
print( result)
6. Question and answering in LangChain
qa_retriever = vector_search.as_retriever(
search_type="similarity",
search_kwargs={
"k": 200,
"post_filter_pipeline": [{"$limit": 25}]
}
)
prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
qa = RetrievalQA.from_chain_type(llm=OpenAI(),chain_type="stuff", retriever=qa_retriever, return_source_documents=True, chain_type_kwargs={"prompt": PROMPT})
docs = qa({"query": "gpt-4 compute requirements"})
print(docs["result"])
print(docs['source_documents'])
Output :
GPT-4 requires a large amount of compute for training, it took 45 petaflops-days of compute to train the model. [Document(page_content='gpt3.5Figure 4. GPT performance on academic and professional exams. In each case, we simulate