Deepseek R1

Introduction:
It’s likely that you might have heard about Deepseek R1, it has shaken up not just the AI community but geopolitics, stock market and many more to come in upcoming days. In this blog post I want you to take you on a journey where we are, where we come from and where we’ll go. So a good history on LLM models, its reigning champion openAI, we’ll talk about reasoning models and finally our star of show deepseek company and it’s R1 series of reasoning models coming up right for you.
Reasoning Model
Now, before we get too far ahead, we need to talk about what "reasoning" means in this context. We're not just talking about spitting out answers. Reasoning, in the AI sense, means the model thinks through a problem before responding. Think of it like this: the model generates a bunch of internal text (tokens) before summarizing those into a final answer. These "reasoning models" are trained to do this, to essentially have an internal "chain of thought" which gets summarized. If you've ever used a "chain of thought" prompting technique, you've already dabbled in this kind of approach. But these models are inherently good at it because they've been trained on massive, high-quality datasets of chains of thought.
So, why is everyone freaking out about Deepseek R1? And how does it compare to OpenAI's O1? Let's dig into that, because that's where the fundamental differences lie.
Quick History on LLM: OpenAI and Scaling Laws
To understand this, we need a little history lesson about OpenAI. They really changed the game with ChatGPT, and the core reason behind that was something called "scaling laws." This concept, championed by Ilya Sutskever (who's no longer with OpenAI and is now focused on finding AGI at his new Superintelligence Institute), basically states that these Transformer models just want to learn. The more data you feed them, and the more computing power you give them, the better they get.
Google originally developed the Transformer architecture, which is generally computable across any modality, a point Andrej Karpathy often emphasizes. OpenAI took this and ran with it. They figured out the recipe: high-quality data + huge compute = better models. And for a few years, it was an amazing journey. We saw models growing atx an incredible pace, culminating in GPT-4.
GPT-4 was monumental. Its achievements were mind-blowing. If we hadn't moving the goalposts for what constitutes Artificial General Intelligence (AGI), we might have called GPT-4 an AGI.
But then... a big gap. After GPT-4, OpenAI seemed to stall. Rumor has it, they hit a fundamental issue with these "one-shot" models. One shot models are the ones that just output tokens directly. You ask a question, it gives an answer. Simple.
Since they weren't seeing the same level of improvement with the traditional training approach, OpenAI started experimenting with something called "inference-time compute." Instead of just focusing on making the model smarter during training, they decided to give it more computing power when it's actually being used (during inference). So when you query the model, it can spend more time (and use more compute) "thinking" before answering.
This is where the reasoning models come in. They leverage this inference-time computation to generate a large number of tokens before summarizing them into a response. And it worked! They found that giving the model more time to "think" during inference allowed it to solve more complex problems than the "one-shot" answers of previous models.
Now, here's the state of play: OpenAI released O1, their first reasoning model. It's the same size as GPT-4, but it's trained differently, on a dataset of human-written reasoning examples. This is a crucial point: OpenAI used supervised fine-tuning, relying on expensive, hand-curated data from human experts.
O1 is powerful, no doubt. It can solve problems GPT-4 struggled with. But that supervised fine-tuning? That's expensive endeavour and alongside with being a huge dense model it shows in the pricing: O1 costs $60 per million output tokens (because it generates so many during inference) or requires a $200/month premium subscription on their platform.
Okay, that was a long detour, but it was necessary to set the stage for our underdog: Deepseek.
Deepseek: Innovation and Architecture
Deepseek is a side project of a Chinese quant fund called High Flyer. They're one of the few non-Big Tech companies with access to a massive number of NVIDIA GPUs, thanks to their visionary leader who's also focused on achieving AGI. These are extremely smart folks with backgrounds in math, programming, and a whole lot of computing power at their disposal. And they started building their own models.
Here's where it gets really interesting. Deepseek's team made some clever architectural changes. Instead of a dense model like OpenAI's, they used a Mixture of Experts (MoE) architecture. Think of it like this: instead of the entire model lighting up every time you ask a question, MoE breaks the model into smaller "experts." R1, for instance, has a massive 671 billion parameters, but only 37 billion are activated for any given query.
Why is this a big deal? Remember, reasoning models rely heavily on inference-time computation. With a dense model, you're activating the whole thing every time. With MoE, you're only using a fraction. This makes R1 much more efficient. It generates tokens faster and cheaper.
But efficiency isn't everything. It also has to be smart. And this is where Deepseek took a different path from OpenAI. Instead of expensive supervised fine-tuning with human experts, they used reinforcement learning (RL).
In essence:
Supervised Fine-tuning (OpenAI's approach): Model learns from pre-defined, correct reasoning examples provided by humans.
Reinforcement Learning (Deepseek approach): Model generates its own reasoning paths, reflects on them from multiple angles, evaluates them based on a reward function, and learns which approaches are most effective. It learns to reason by exploring and discovering, rather than just mimicking.
In very simple terms, RL is like training a dog. You don't give it a manual; you give it an environment, a reward function, and let it figure things out. Deepseek used their powerful V3 model (think of it as their version of GPT-4, although not directly comparable in intelligence) to generate reasoning chains, then used a reward function to guide it. This is called pure RL, where the model itself determines the best tokens to generate to maximize the reward, without human intervention.
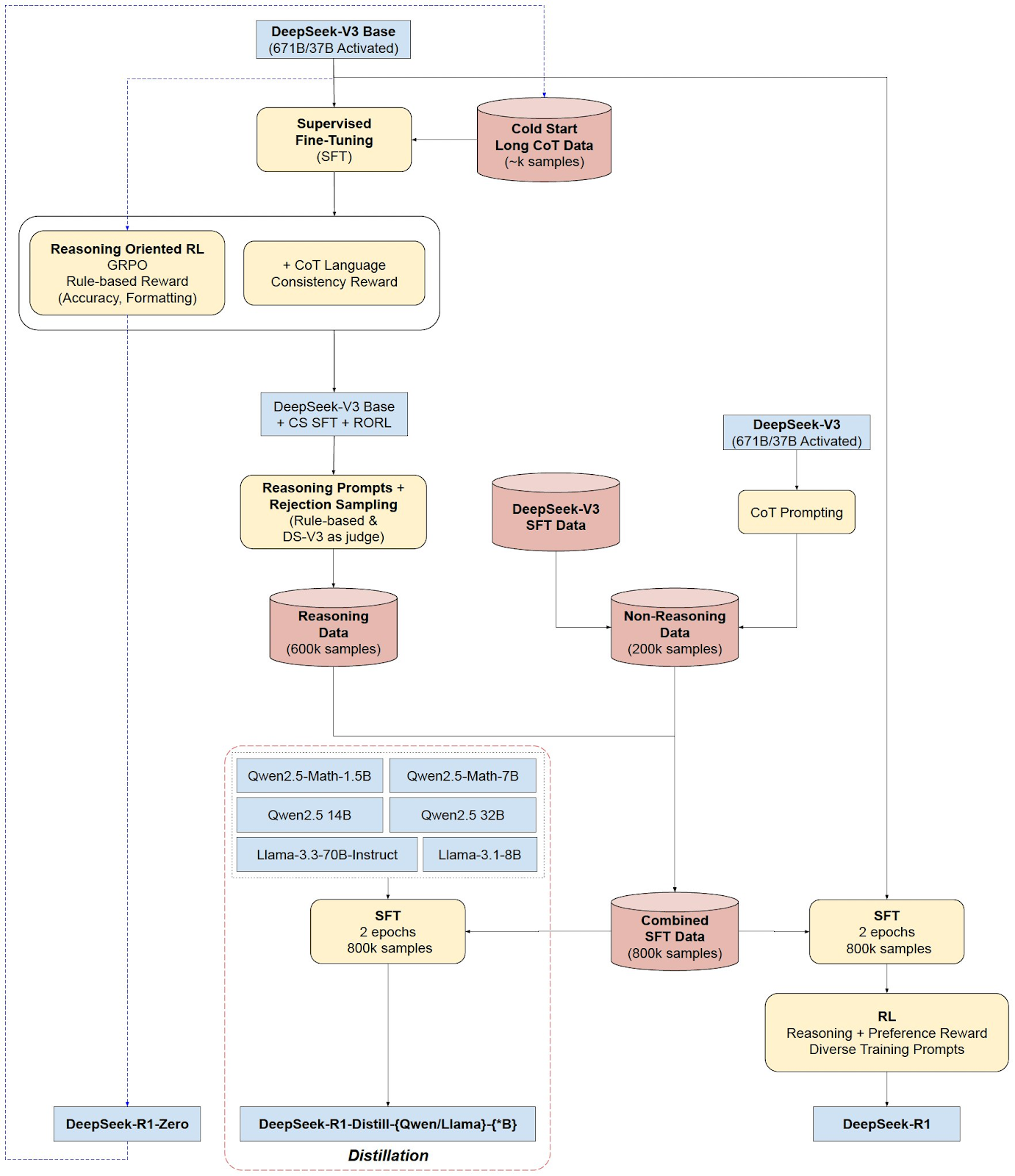
Here is text that can help you understand the training flow:
- DeepSeek-V3 Base + Pure RL = Deepseek-R1-Zero
- Use R1-Zero to generate Long CoT Cold Start Data.
- DeepSeek-V3 Base + SFT (Cold Start Data) + RL → Checkpoint 1
- Checkpoint 1 + RL (GRPO + Language Consistency) → Checkpoint 2
- Checkpoint 2 used to Generate Data (Rejection Sampling) 600K
- DeepSeek-V3 Base + CoT Prompting → Non-Reasoning Data 200k
- Checkpoint 3 + RL (Reasoning + Preference Rewards) + SFT Data 800K→ DeepSeek-R1
Now, Deepseek already has 800,000 high-quality reasoning + non-reasoning tokens. They used this dataset to fine-tune several open-source models, which are called R1-distilled which including:
1.5B, 7B, 14B, 32B Qwen model and 70B LLaMa. Basically taking this open source model and doing SFT on these models generating reasoning models of these popular open source models. This one can run locally on their system.
So, alongside R1 and R1-Zero, they released six additional models, making powerful reasoning capabilities available to a much wider audience.
Conclusion
The result? Deepseek R1. A model that's:
- Cheaper: $3 per million output tokens, compared to O1's $60.
- Competitive: Matches or beats O1 on several benchmarks, including math (which is significant, given that O1's math dataset was human-curated).
- Efficient: Trained on a smaller GPU cluster (2048 GPUs compared to potentially much larger clusters used by OpenAI).
- Accessible: They open-sourced several smaller models distilled from R1, meaning you can run powerful reasoning models locally.
This last point has major geopolitical implications. The community has figured out how to use six Apple Mac Studio Ultras, connected via Thunderbolt, to run a slightly quantized version of R1. They're using a framework called MLX Distributed, which allows you to distribute a large language model across multiple devices.
https://x.com/awnihannun/status/1881412271236346233
Think about that. For around $10,000 (or potentially more), you can have your own personal setup that rivals the capabilities of OpenAI's O1. This challenges the dominance of Big Tech and puts powerful AI in the hands of more people. It could potentially disrupt the AI hardware market, which is why companies like NVIDIA might be concerned.
And that's the story of Deepseek R1. It's a story of clever engineering, a different approach to training, and a potential shift in the balance of power in the AI world. It's a testament to the fact that there's more than one way to achieve impressive results in AI, and that sometimes, the underdogs can come out on top. This release hints at a future where advanced AI models are more democratized and not solely controlled by large corporations.
Thanks for listening. That's a wrap!